

When you develop a large number of files to use as web resources, you can save yourself the work of manually adding them. In ZMP, resources can be imported into the platform via our API, web scraping, and file imports.
Enabling FTP Imports
If your site already has enabled file imports for users or exports of event or user data via FTP, this step is already done! If not, contact your Zeta Account Manager to enable file imports for your ZMP instance.
Getting FTP credentials
Once enabled, you’ll find an FTP username and password in the Settings > Integrations section of the platform. You will use these credentials to access the Zeta-Hosted FTP server for delivering your data file:
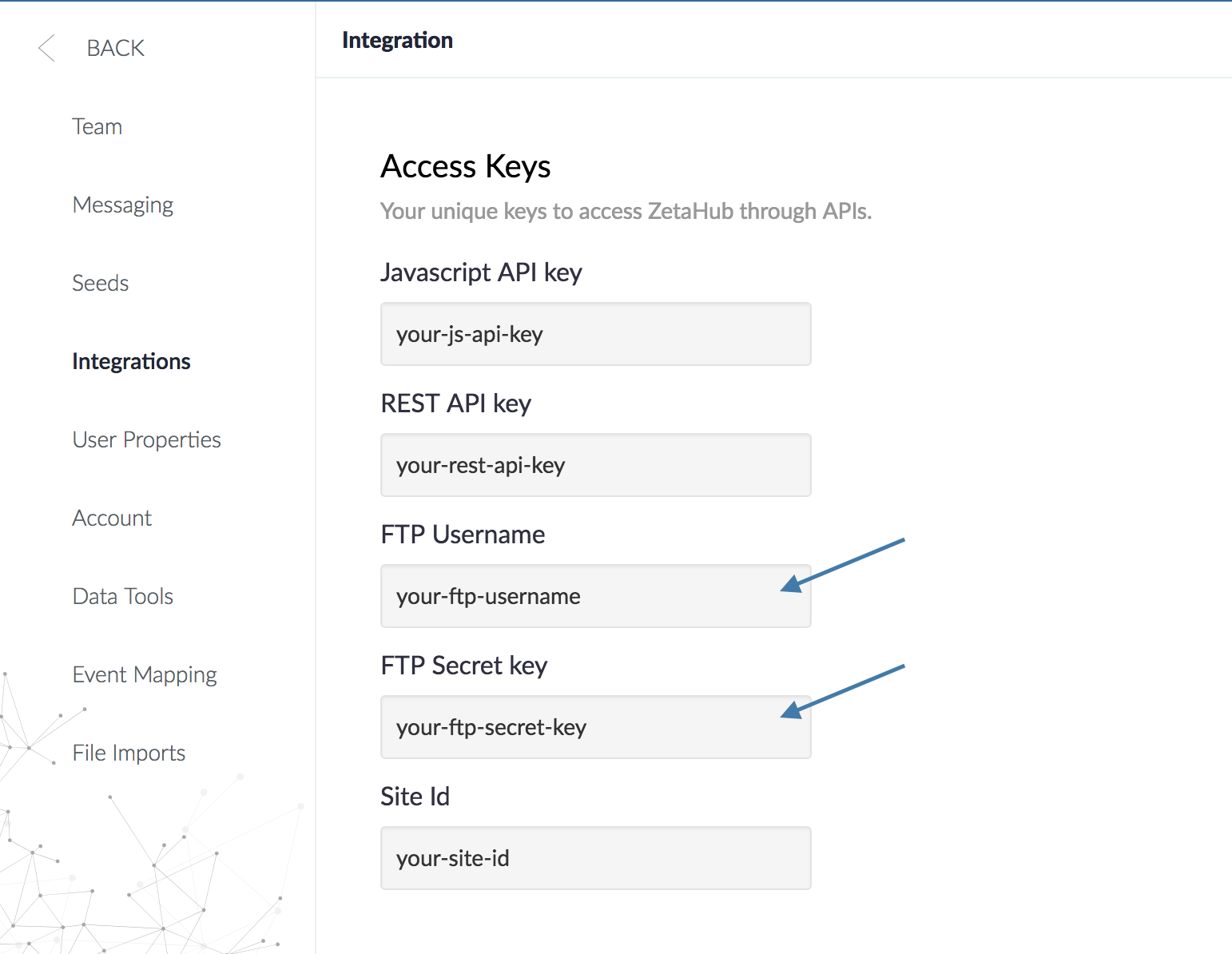
Connecting to the FTP Server
Connect to the Zeta FTP server with your FTP credentials and find the Events folder:
Protocol: SFTP
Hostname: sftp.boomtrain.net
Logon Type: User/Password Authentication
Directory: /resources
All properly formatted data files dropped into this directory will start being processed into your Zeta account within a couple of minutes. Zeta’s systems will start processing your file within five minutes of a completed upload to this server. To ensure that your file has been completely transferred to Zeta’s servers, the server implements a short delay from the time your file finishes uploading until the start of processing.
File Formats
To create a folder within FTP, navigate to Settings > Integrations > Keys & Apps and log in using the FTP User Name and FTP Key. On the right-hand side of the FTP connection, right-click on the Remote Site to Create directory. Name your folder accordingly.
JSONL Files
JSON Line Files should be formatted as UTF-8-encoded text files with a .jsonl extension that consist of newline-delimited JSON objects (or an archive file containing valid JSONL files). Each line in the file is an object representing resources to upsert. For Resource Ingestion, only the following three fields are required:
-
resource-id -
resource-type -
url
-
All other resource fields, such as
title,thumbnail,pubDate, and any custom fields, are optional and may be included as needed. -
Although
pubDatemay be required by your resource configuration, it is not required as part of the import file.
If a file fails validation according to these requirements, the file processing status should be marked as "failed" with the reason for the failure noted in the status log.
Sample JSONL File:
{
"resource-type": "article",
"resource-id": "1234",
"url": "https://example.com/articles/1234"
}
{
"resource-type": "product",
"resource-id": "2345",
"url": "https://example.com/products/2345",
"title": "My Product",
"price": 12.45
}
Managing Variants in JSONL Files
Variants of a given resource are managed by specifying a "variants" object in the line with any number of variants in it. Only variants that are included in this object will be augmented; variants not specified in the variants object will remain unchanged.
Variants should only contain fields that are compatible with existing resource fields (see Get Resource Fields for more details). That is, any variant's fields MUST match an existing field. Variants are not required to have any specific fields.
Specifying the same variant key more than once on the same line will result in the last object specified with that variant being the value set. That means a put with data:
{
"resource-type": "product",
"resource-id": "1234",
"url": "https://example.com/products/1234",
"variants": {
"1234a": {
"color": "Red",
"size_1": 32,
"size_2": 30
},
"1234a": {
"color": "Blue"
}
}
}
-
The above would result in variant
1234ahaving one property color: Blue. -
Setting a variant's value to the empty object,
{}, will delete that variant. Other unspecified variants of the resource will remain unchanged.
Remove Variant from Resource
{
"resource-type": "product",
"resource-id": "1234",
"url": "https://example.com/products/1234",
"variants": {
"1234a": {}
}
}
CSV Files
CSV Files should be formatted as UTF-8-encoded text files with a .csv extension (case-insensitive) with a single header row designating each column. Each non-header row will represent a resource to be upserted for the site. Three columns are required: resource-id, resource-type, and url. Note that there are no restrictions on the filename, other than the extension, which must be .jsonl or .csv or an archive file containing valid files in one of those formats.
The following other requirements will be in place for CSVs:
-
Column headers are limited to a maximum of 256 characters.
-
If a file fails validation according to these requirements, the file processing status should be marked as "failed" with the reason for the failure noted in the status log.
-
Each row in the file, with a guaranteed
resource-typeandresource-idfield, will be upserted. As is the case with the Create/Update Resource API, any resource fields specified in each row of the file will be updated with the new values specified. If an existing field is not in the row, it will remain unchanged. Note that this rule is excepted by the variant deletion method.
Field Enclosures and Escape Characters
The double-quote character " may be used to enclose fields. This means that this three-column file is acceptable:
resource-type,resource-id,url,title
article,1234,https://example.com/articles/1234,"My Title, Which Has Commas"
In this case, the title of that resource will resolve to the value My Title, Which Has Commas.
If a double-quote character is used inside of an enclosed field, it must be preceded by another double-quote character, per the RFC-4180 specification. Thus, this three-column file is acceptable:
resource-type,resource-id,url,title
article,1234,https://example.com/articles/1234,"My Title, Which Has ""Quotes"""
In this case, {{title}} will resolve to the value My Title, which has "Quotes".
Managing Variants in CSV Files
Variants of a given resource are managed by specifying a "variant" column in the file in addition to the resource-type and resource-id. If the variant column for a given row is empty, the row will augment the parent resource; if it is present and specified, the variant specified in the row will be augmented; variants not specified by this row will not be affected. Variants should only contain fields that are compatible with existing resource fields (see Get Resource Fields for more details). That is, any variant's fields MUST match an existing field. Variants are not required to have any specific fields. Specifying only the resource-type, resource-id, and variant, and nothing else, will clear that specific variant if it already exists.
Example:
resource-id,resource-type,url,variant,title,price
1234,product,https://example.com/products/1234,1234a,Variant A Title,10
1234,product,https://example.com/products/1234,,Parent Title,15
1234,product,https://example.com/products/1234,1234b,Variant B Title,20
1234,product,https://example.com/products/1234,1234c,,
Resulting Resource:
{
"resource_type": "product",
"resource_id": "1234",
"url": "https://example.com/products/1234",
"title": "Parent Title",
"price": 15,
"variants": {
"1234a": {
"title": "Variant A Title",
"price": 10
},
"1234b": {
"title": "Variant B Title",
"price": 20
}
}
}
Variant 1234c was cleared and therefore no longer exists.
Archive Files for Multi-File Processing
Files may be dropped individually or bundled into an archive/compressed file that has one of the following compression formats:
-
zip (.zip)
-
gzip (.gz, .tar.gz, .tgz)
-
bzip2 (.bz2, .tbz2, .tar.bz2)
Each item in the archive should be a valid file at the top level of the archive (no sub-directories will be traversed). Any files that fail validation in an archive will trigger a warning state in the status log, indicating that the specific files failed to process, but the rest of the successfully processable files in the archive will proceed.